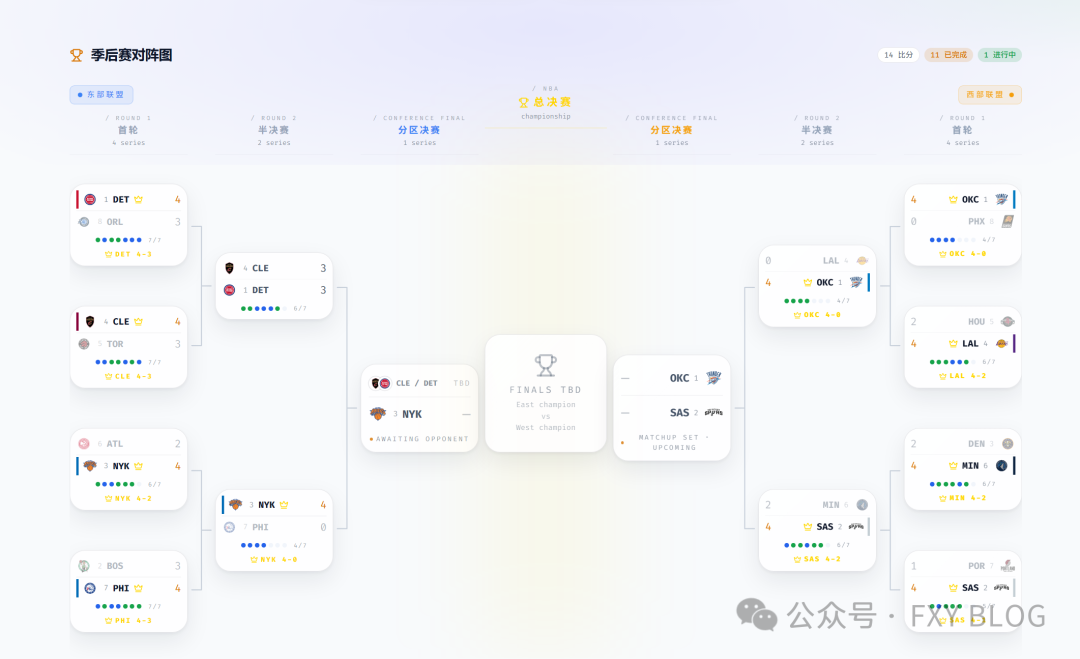
type
Post
status
Published
date
Apr 13, 2026
slug
NLP
summary
tags
推荐
思考
category
技术分享
icon
password
本章系统梳理了自然语言处理的定义、发展脉络、典型任务以及文本表示技术的演进。通过学习,我对NLP从规则驱动到统计建模、再到深度学习主导的范式转变建立了清晰的技术框架,尤其理解了文本表示方法如何直接决定下游任务的性能。
1. NLP的定义与核心挑战
NLP旨在让计算机理解、解释并生成人类自然语言,是人工智能中融合计算机科学、语言学、统计学和认知科学的交叉领域。其根本目标是突破符号序列与语义之间的映射障碍,实现从表层语法到深层语义、语境乃至情感文化的建模。
核心挑战在于语言的歧义性、上下文依赖、隐喻讽刺处理以及跨文化差异。以中文为例,由于没有空格分隔,中文分词成为预处理的关键瓶颈,直接影响后续词性标注、命名实体识别和句法分析的准确率。
2. NLP技术发展历程
NLP发展可分为三个阶段:
- 早期规则驱动阶段:以机器翻译为起点,依赖词典查找和手工规则。图灵测试的提出奠定了智能评估基准,但受限于计算资源,系统只能处理简单词序,泛化能力很弱。
- 符号主义与统计建模阶段:符号派强调形式语言和逻辑范式,统计派则引入概率模型。随着计算能力提升,统计方法逐渐主导,隐马尔可夫模型和条件随机场取代了大量手工规则,大幅降低了系统维护成本。
- 神经网络与预训练时代:循环神经网络、长短时记忆网络及注意力机制的引入解决了长距离依赖问题。Word2Vec开启了分布式词向量时代,BERT基于Transformer的双向预训练实现了上下文动态表示,后续GPT系列通过海量参数与自回归生成,达到了接近人类水平的文本生成能力。Transformer架构彻底抛弃了循环结构,成为当前主流。
3. 主要NLP任务
本章列举的核心任务构成了NLP流水线的完整链路:
- 中文分词与子词切分:分词需处理歧义与未登录词,子词方法通过频次统计将词汇拆解为可复用单元,有效缓解生僻词问题。例如unhappiness可分解为un、happi、ness,保留了词素语义。
- 词性标注:基于隐马尔可夫模型、条件随机场或双向长短时记忆网络模型为每个词分配标签,是句法分析的前置步骤。
- 文本分类:从特征工程到端到端神经网络,实现情感分析、主题分类等应用。
- 命名实体识别:序列标注任务,输出实体边界与类别,是知识图谱构建的基础。
- 关系抽取:在实体基础上识别语义关系,常采用联合抽取或流水线方式。
- 文本摘要:抽取式依赖句子重要度排序,生成式则基于序列到序列模型加注意力机制实现语义重构。
- 机器翻译与自动问答:前者追求语义保真与流畅度,后者涵盖检索式、知识库式与生成式范式,均高度依赖上下文建模。
4. 文本表示技术演进
文本表示是NLP性能的决定性因素,本章重点对比了以下方法:
- 向量空间模型:以词频或逆文档频率构造高维稀疏向量,维度常达万级,存在维度灾难和数据稀疏问题,同时忽略了词序与语义关联。
- N-gram语言模型:基于马尔可夫假设建模条件概率,计算简单但高阶时参数爆炸,无法捕捉长程依赖。
- Word2Vec:通过连续词袋模型或跳元模型学习上下文关系,生成低维稠密向量,捕捉语义相似性,但仍是静态表示,无法处理一词多义。
- ELMo:采用双向长短时记忆网络语言模型预训练,在下游任务中提取上下文相关向量,实现了动态表示,为后续预训练模型奠定了基础。
Happy-LLM
Description
- 作者:FXY
- 链接:https://www.xpy.me/article/NLP
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。